

复合类型
| 类型 | 名称 | 长度 | 默认值 | 说明 |
|---|---|---|---|---|
| pointer | 指针 | nil | ||
| array | 数组 | 0 | ||
| slice | 切片 | nil | 引⽤类型 | |
| map | 字典 | nil | 引⽤类型 | |
| struct | 结构体 |
指针
Go语言虽然保留了指针,但与其它编程语言不同的是:
- 默认值 nil,没有 NULL 常量
- 操作符 "&" 取变量地址, "*" 通过指针访问目标对象
- 不支持指针运算,不支持 "->" 运算符,直接⽤ "." 访问目标成员
基本操作
go
package main
import "fmt"
func main() {
var a int = 10 //声明一个变量,同时初始化
fmt.Printf("&a = %p\n", &a) //操作符 "&" 取变量地址
var p *int = nil //声明一个变量p, 类型为 *int, 指针类型
p = &a
fmt.Printf("p = %p\n", p)
fmt.Printf("a = %d, *p = %d\n", a, *p)
*p = 111 //*p操作指针所指向的内存,即为a
fmt.Printf("a = %d, *p = %d\n", a, *p)
/**
&a = 0xc00000a0b8
p = 0xc00000a0b8
a = 10, *p = 10
a = 111, *p = 111
*/
}new分配内存
其实也很好理解,你只声明p它是指针类型的变量,但是它并没有指向内存,所以需要用new来开辟一个新的内存。
go
package main
import "fmt"
func main() {
var p1 *int
p1 = new(int) //p1为*int 类型, 指向匿名的int变量
fmt.Println("*p1 = ", *p1) //*p1 = 0
p2 := new(int) //p2为*int 类型, 指向匿名的int变量
*p2 = 111
fmt.Println("*p2 = ", *p2) //*p1 = 111
}指针做函数参数
go
package main
import "fmt"
func swap01(a, b int) {
a, b = b, a
fmt.Printf("swap01 a = %d, b = %d\n", a, b)
}
func swap02(x, y *int) {
*x, *y = *y, *x
}
func main() {
a := 10
b := 20
//swap01(a, b) //值传递 a = 10, b = 20
swap02(&a, &b) //变量地址传递 a = 20, b = 10
fmt.Printf("a = %d, b = %d\n", a, b)
}数组
创建数组
go
package main
import "fmt"
func main() {
//创建数组
var x [10]int
fmt.Printf("数组打印 %v\n", x) //[0 0 0 0 0 0 0 0 0 0]
fmt.Printf("类型 %T\n", x) //[10]int
//初始化
a := [3]int{1, 2} // 未初始化元素值为 0
b := [...]int{1, 2, 3} // 通过初始化值确定数组长度
c := [5]int{2: 100, 4: 200} // 通过索引号初始化元素,未初始化元素值为 0
fmt.Println(a, b, c) //[1 2 0] [1 2 3] [0 0 100 0 200]
//支持多维数组
d := [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
e := [...][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}} //第二维不能写"..."
f := [4][2]int{1: {20, 21}, 3: {40, 41}} //单独指定值
g := [4][2]int{1: {0: 20}, 3: {1: 41}}
fmt.Println(d) //[[10 11] [20 21] [30 31] [40 41]]
fmt.Println(e) //[[10 11] [20 21] [30 31] [40 41]]
fmt.Println(f) //[[0 0] [20 21] [0 0] [40 41]]
fmt.Println(g) //[[0 0] [20 0] [0 0] [0 41]]
}常用操作
go
package main
import "fmt"
func main() {
var a [10]int
for i := 0; i < 10; i++ {
a[i] = i + 1
fmt.Printf("a[%d] = %d\n", i, a[i])
}
//range具有两个返回值,第一个返回值是元素的数组下标,第二个返回值是元素的值
for i, v := range a {
fmt.Println("a[", i, "]=", v)
}
//内置函数 len(长度) 和 cap(容量) 都返回数组⻓度 (元素数量):
b := [10]int{}
fmt.Println(len(b), cap(b)) //10 10
}在函数间传递数组
在函数之间传递变量时,总是以值的方式传递的。如果这个变量是一个数组,意味着整个数组,不管有多长,都会完整复制,并传递给函数。
下面的这个代码就说明了数组是值传递。
go
package main
import "fmt"
func modify(array [5]int) {
array[0] = 10 // 试图修改数组的第一个元素
//In modify(), array values: [10 2 3 4 5]
fmt.Println("In modify(), array values:", array)
}
func main() {
array := [5]int{1, 2, 3, 4, 5} // 定义并初始化一个数组
modify(array) // 传递给一个函数,并试图在函数体内修改这个数组内容
//In main(), array values: [1 2 3 4 5]
fmt.Println("In main(), array values:", array)
}但是我如果我们想要实现对象传递的话,也是可以的,就需要传递指针来实现
go
package main
import "fmt"
func modify(array *[5]int) {
(*array)[0] = 10
//In modify(), array values: [10 2 3 4 5]
fmt.Println("In modify(), array values:", *array)
}
func main() {
array := [5]int{1, 2, 3, 4, 5} // 定义并初始化一个数组
modify(&array) // 传递给一个函数,并试图在函数体内修改这个数组内容
//In main(), array values: [10 2 3 4 5]
fmt.Println("In main(), array values:", array)
}slice
数组的长度在定义之后无法再次修改;数组是值类型,每次传递都将产生一份副本。显然这种数据结构无法完全满足开发者的真实需求。Go语言提供了数组切片(slice)来弥补数组的不足。
切片并不是数组或数组指针,它通过内部指针和相关属性引⽤数组⽚段,以实现变⻓⽅案。
slice并不是真正意义上的动态数组,而是一个引用类型。slice总是指向一个底层array,slice的声明也可以像array一样,只是不需要长度。
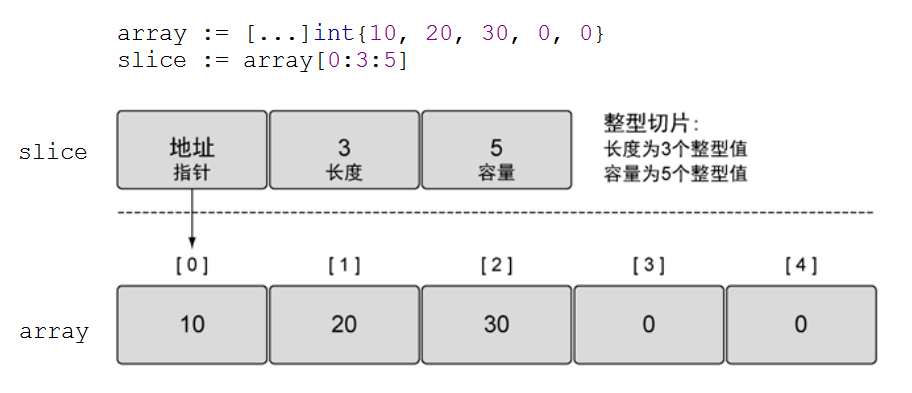
slice和数组的区别:声明数组时,方括号内写明了数组的长度或使用...自动计算长度,而声明slice时,方括号内没有任何字符。
go
package main
import "fmt"
func main() {
var s1 []int //声明切片和声明array一样,只是少了长度,此为空(nil)切片
s2 := []int{}
//make([]T, length, capacity) //capacity省略,则和length的值相同
var s3 []int = make([]int, 0)
s4 := make([]int, 0, 0)
s5 := []int{1, 2, 3} //创建切片并初始化
//用array创建slice
array := [...]int{1, 2, 3, 4, 5}
s6 := array[1:3:5] //从索引1:3切片,容量的话为5
fmt.Printf("s1 = %T , %v \n", s1, s1)
fmt.Printf("s2 = %T , %v \n", s2, s2)
fmt.Printf("s3 = %T , %v \n", s3, s3)
fmt.Printf("s4 = %T , %v \n", s4, s4)
fmt.Printf("s5 = %T , %v \n", s5, s5)
fmt.Printf("s6 = %T , %v ,len = %d \n", s6, s6, len(s6))
/**
s1 = []int , []
s2 = []int , []
s3 = []int , []
s4 = []int , []
s5 = []int , [1 2 3]
s6 = []int , [2 3] ,len = 2
*/
}常用api
截取
go
package main
import "fmt"
func main() {
slice := []int{1, 2, 3, 4, 5, 6}
xx := slice[1:3:4] //从切片s的索引位置low到high处所获得的切片,len=high-low,cap=max-low
fmt.Printf("len= %v cap= %v\n", len(xx), cap(xx)) //len= 2 cap= 3
}示例说明:
shell
array := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}| 操作 | 结果 | len | cap | 说明 |
|---|---|---|---|---|
| array[:6:8] | [0 1 2 3 4 5] | 6 | 8 | 省略 low |
| array[5:] | [5 6 7 8 9] | 5 | 5 | 省略 high、 max |
| array[:3] | [0 1 2] | 3 | 10 | 省略 high、 max |
| array[:] | [0 1 2 3 4 5 6 7 8 9] | 10 | 10 | 全部省略 |
append新增
append函数向 slice 尾部添加数据,返回新的 slice 对象:
go
package main
import "fmt"
func main() {
var s1 []int //创建nil切换
//s1 := make([]int, 0)
s1 = append(s1, 1) //追加1个元素
s1 = append(s1, 2, 3) //追加2个元素
s1 = append(s1, 4, 5, 6) //追加3个元素
fmt.Println(s1) //[1 2 3 4 5 6]
s2 := make([]int, 5)
s2 = append(s2, 6)
fmt.Println(s2) //[0 0 0 0 0 6]
s3 := []int{1, 2, 3}
s3 = append(s3, 4, 5)
fmt.Println(s3) //[1 2 3 4 5]
}append函数会智能地底层数组的容量增长,一旦超过原底层数组容量,通常以2倍容量重新分配底层数组,并复制原来的数据:
go
package main
import "fmt"
func main() {
s := make([]int, 0, 1)
c := cap(s)
for i := 0; i < 50; i++ {
s = append(s, i)
if n := cap(s); n > c {
fmt.Printf("cap: %d -> %d\n", c, n)
c = n
}
}
/*
cap: 1 -> 2
cap: 2 -> 4
cap: 4 -> 8
cap: 8 -> 16
cap: 16 -> 32
cap: 32 -> 64
*/
}copy
函数 copy 在两个 slice 间复制数据,复制⻓度以 len 小的为准,两个 slice 可指向同⼀底层数组。
go
package main
import "fmt"
func main() {
// 创建一个包含10个整数的数组
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 创建从索引8开始到末尾的切片
s1 := data[8:] // {8, 9}
// 创建从开始到索引5(不包括5)的切片
s2 := data[:5] // {0, 1, 2, 3, 4}
// 将s1拷贝到s2,s2的长度决定了能拷贝多少元素
copy(s2, s1) // 拷贝2个元素到s2的前两个位置
fmt.Println(s2) // [8 9 2 3 4]
fmt.Println(data) // [8 9 2 3 4 5 6 7 8 9]
}切片和数组的关系
go
package main
import "fmt"
func main() {
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s[2:5] //[2 3 4]
s1[2] = 100 //修改切片某个元素改变底层数组
fmt.Println(s1, ">>>>>>>>", s) //[2 3 100] >>>>>>>> [0 1 2 3 100 5 6 7 8 9]
s2 := s1[2:6] // 新切片依旧指向原底层数组 [100 5 6 7]
s2[3] = 200
fmt.Println(s2) //[100 5 6 200]
fmt.Println(s) //[0 1 2 3 100 5 6 200 8 9]
}map
map格式为:map[keyType]valueType,在一个map里所有的键都是唯一的
注意:map是无序的,我们无法决定它的返回顺序,所以,每次打印结果的顺利有可能不同。
map的创建
go
package main
import "fmt"
func main() {
var m1 map[int]string //只是声明一个map,没有初始化, 此为空(nil)map
fmt.Println(m1 == nil) //true
//m1[1] = "mike" //err, panic: assignment to entry in nil map
//m2, m3的创建方法是等价的
m2 := map[int]string{}
m3 := make(map[int]string)
fmt.Println(m2, m3) //map[] map[]
m4 := make(map[int]string, 10) //第2个参数指定容量
fmt.Println(m4) //map[]
//1、定义同时初始化
var m5 map[int]string = map[int]string{1: "mike", 2: "yoyo"}
fmt.Println(m5) //map[1:mike 2:yoyo]
//2、自动推导类型 :=
m6 := map[int]string{1: "mike", 2: "yoyo"}
fmt.Println(m6)
}map遍历
go
package main
import "fmt"
func main() {
m1 := map[int]string{1: "mike", 2: "yoyo"}
//迭代遍历1,第一个返回值是key,第二个返回值是value
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
//1 ----> mike
//2 ----> yoyo
}
//迭代遍历2,第一个返回值是key,第二个返回值是value(可省略)
for k := range m1 {
fmt.Printf("%d ----> %s\n", k, m1[k])
//1 ----> mike
//2 ----> yoyo
}
//判断某个key所对应的value是否存在, 第一个返回值是value(如果存在的话)
value, ok := m1[1]
fmt.Println("value = ", value, ", ok = ", ok) //value = mike , ok = true
value2, ok2 := m1[3]
fmt.Println("value2 = ", value2, ", ok2 = ", ok2) //value2 = , ok2 = false
}删除
go
package main
import "fmt"
func main() {
m1 := map[int]string{1: "mike", 2: "yoyo", 3: "lily"}
//迭代遍历1,第一个返回值是key,第二个返回值是value
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
//1 ----> mike
//2 ----> yoyo
//3 ----> lily
}
delete(m1, 2) //删除key值为3的map
for k, v := range m1 {
fmt.Printf("%d ----> %s\n", k, v)
//1 ----> mike
//3 ----> lily
}
}